
There’s no denying that Microsoft Azure plays a huge role in today’s digital infrastructure. Microsoft Azure is the world’s second-largest cloud platform, and many businesses across the world rely on it. Microsoft Azure outage affected several major companies and their services, including Slack, Snapchat and Reddit. It was the second biggest outage this month, happened on Wednesday, October 29.
According to the Downdetector.com , a platform to check the online service statuses , over 16,000 users reported being unable to access azure and Microsoft 365 was down for nearly 9000 users.
In this blog, we are going to explore why this outage happened, it’s root cause, its impact and how it might influence future cloud adoption. But before explore this outage in detail, it is important to understand what Microsoft Azure actually is.
What is Microsoft Azure?
Microsoft Azure is a cloud platform developed by Microsoft that provides cloud services such as databases, storage, AI tools and virtual machines. It allows businesses and developers to build, deploy and manage applications without maintaining physical hardware. Many big companies including Adobe, Coca-Cola and HP Inc. use Microsoft Azure services.
Because so many global companies depend on Azure for their daily operations, when it fails, the effect spread quickly across the entire world.

Microsoft Azure Outage :What Happened and Why?
On October 29,2025, users around the world started reporting problems with Microsoft services. Many users reported that Microsoft 365 apps, such as Team and Outlook were not responding, and several were unable to access Azure Virtual Machines.
Soon after, a number of other well-known apps began to experience connectivity problems, including Slack, Reddit, Snapchat, and Starbucks app.

Within a few minutes, social media platforms like X(formerly twitter) were flooded with complaints and outage reports. Tech websites confirmed that the issue was not limited to one region, it was affecting North America, Europe, Asia, and parts of India as well.
After this outage, the issues reported by users included:

- Slow loading Applications: Popular services like Microsoft Teams, Outlook, and Copilot faced login errors or became temporarily unavailable.
- Failed database connections: Users were unable to access or update their Azure SQL Databases, leading to delays in data operations.
- Delayed service deployment: Developer faced interruptions while deploying updates or launching new services through Azure DevOps.
- Authentication and login failures: Users experienced issues signing into Microsoft 365, Azure Portal, and other cloud-based applications due to identity service disruptions.
- Disrupted virtual machine operations: Many businesses reported their Azure Virtual Machines becoming unresponsive or going offline.
Root Cause:
The main reason behind this outage was a DNS-related issue caused by a configuration error inside Microsoft’s Azure Front Door (AFD) service. It was similar to the AWS outage that happened on 20 October. Because of this outage many popular platforms like ChatGPT, Perplexity, Canva were affected globally.
Let’s first understand what DNS and Azure Front Door actually are:
- DNS(Domain Name System): It is like the internet’s address book which converts the website name into numerical address. Every website on the internet has unique IP address (148,325.189.15),which tells your browser where that website is hosted. But it is hard for people to remember numbers, DNS makes it easier by translating domain names like www.microsoft.com into those IP addresses automatically.
- Azure Front Door : It is a system that routes internet traffic quickly and securely across Microsoft’s global network.
During a routing configuration update in DNS, an error was introduced into Azure Front Door’s settings, which meant that users couldn’t be directed to the correct servers. This minor faulty configuration in Azure’s network was the main reason of this global outage. It’s important to note that this was not a cyberattack or any kind of security breach, it was a technical human error during an internal update.
How Microsoft resolved this issue:
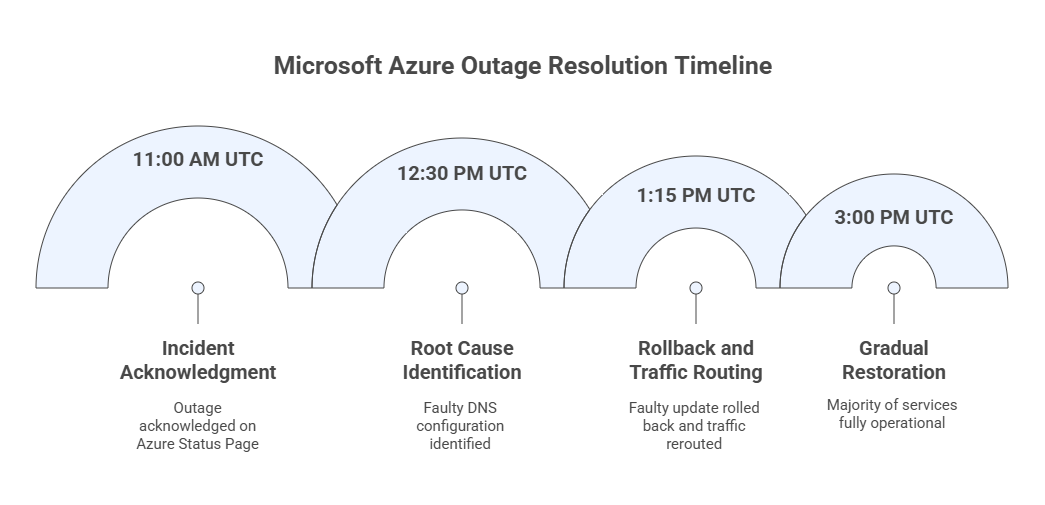
Microsoft resolved the outage very quickly and systematically. Let’s take a look at how they managed it along with the timeline:
- Incident Acknowledgment: Around 11:00 AM UTC, Microsoft acknowledged the outage on its Azure Status Page. The company confirmed that multiple Azure services and Microsoft 365 were facing connectivity issues, and engineers were actively investigating the cause.
- Root cause Identification: After initial analysis, at 12:30 PM UTC, Microsoft’s engineering team identified that the problem stemmed from faulty DNS configuration within Azure Front Door(AFD).This Faulty misconfiguration disrupted DNS lookups, preventing users from reaching Azure hosted applications.
- Rollback and Traffic routing: Engineers started rolling back the faulty update and began rerouting DNS traffic through unaffected network routes at 1:15 PM UTC .This step helped restore connectivity for many users gradually.
- Gradual Restoration: Microsoft carefully restored services region by region. By mid-afternoon at 3:00 PM UTC, the majority of affected services were fully operational again.
Later that day, after resolving the outage, Microsoft announced that it would release a Post Incident Report (PIR). This report will provide in-depth details about the root cause, preventing measures, and improvements to Azure’s update and validation process.
A Wake-Up call for Businesses:
For many businesses this outage was a wake-up call. Within a few hours, it felt like the internet had slowed down everywhere. This incident reminded us one simple truth that no organization should completely depend on a single technology or cloud provider. After this outage, many companies are planning to lean more toward multi-cloud or hybrid cloud models, so that if one cloud platform goes down ,the other platform can keep things running smoothly.
Cloud providers like Microsoft, Google and Amazon are working on improving their systems to make them more reliable so that we don’t have to face same issue in future again.
Conclusion:
In this blog, we explored what caused the massive Microsoft cloud outage ,how it impacted global users, and how Microsoft worked swiftly to bring business online back within hours.
This event taught us even biggest and most powerful cloud platform can also face downtime and any system can stumble. But what truly matters is how quickly and effectively such issues are identified, resolved, and learned from to prevent them from happening again.
