
Resources
“How many times has this happened to you? You upload a file to Amazon S3 and then accidentally overwrite it with the old version. Now, you’re left wondering if your new changes will be lost and what can be done to ensure that doesn’t happen.”
In this blog post, we will cover how Amazon S3 versioning works and why it is so important. We will also be covering the benefits of using Amazon S3 for your website or application’s storage needs. This is a great read if you want to know more about how these services work and what they offer.
In your journey to understand AWS S3 versioning, it’s essential to refer to the Amazon S3 FAQ, a valuable resource for answering common questions about this robust storage service. AWS S3 versioning, often referred to as S3 bucket versioning or S3 object versioning, is a critical feature that allows you to keep multiple iterations of your stored data. By enabling versioning, you gain the ability to recover from accidental deletions, protect against data corruption, and meet compliance requirements. In this beginner’s guide, we’ll delve into the details of how AWS S3 versioning works and explore its benefits for ensuring data durability and integrity in your S3 buckets.
Versioning
To begin our discussion of Amazon S3 versioning, we need to understand what we mean by the term versioning. Versioning allows you to keep the same object, even if it changes. For example, say that you have an object (object1) currently stored in a bucket. If you upload a new version of this object to that bucket without having enabled vorversionimgstalling on your original binary file will automatically replace the old one with any newer versions uploaded later. This is not good for when mistakes are made! Enabling Versioning ensures no data loss by keeping all previous versions.
Amazon S3 Object Versioning: Data Resilience
Amazon S3 object versioning is a feature that provides an additional layer of data protection and recovery for objects stored in Amazon S3 buckets. When S3 object versioning is enabled for a bucket, each time an object is overwritten or deleted, a new version of the object is automatically created. This allows users to preserve and access previous versions of objects, facilitating easy recovery in case of accidental data loss or corruption. With S3 object versioning, organizations can maintain a complete history of changes made to objects over time, promoting data resilience and enabling effective management of object-level versioning.
What is Amazon S3 versioning?
Amazon S3 versioning is a feature that enables you to keep multiple copies of an object in your Amazon S3 bucket. You can then access these objects using their respective versions, enabling easy collaboration on specific files or changes made over time while saving the current state for the latest release.
Amazon Simple Storage Service (S3) provides storage through web services interfaces and helps businesses build scalable applications more efficiently by removing infrastructure concerns such as hosting servers, capacity provisioning, and scaling up/down resources according to business needs.

Using buckets that are versioning-enabled, you can recover from accidental actions:
- Objects are not deleted permanently but are marked as deleted as the current version. It is easy to restore previous versions.
- A new version of an object will be created when you overwrite an existing one. You can easily restore previous versions.
What are the objects and buckets in AWS Versioning?
A bucket is a simple storage container for objects. An object can be any file and the data that describes it, such as name or size. To store an object in Amazon S3 you create a bucket to put them into then upload the files from your computer directly into it. Once they’re there you’ll have access to download and move them around at will without having issues with loading times like on traditional web servers!
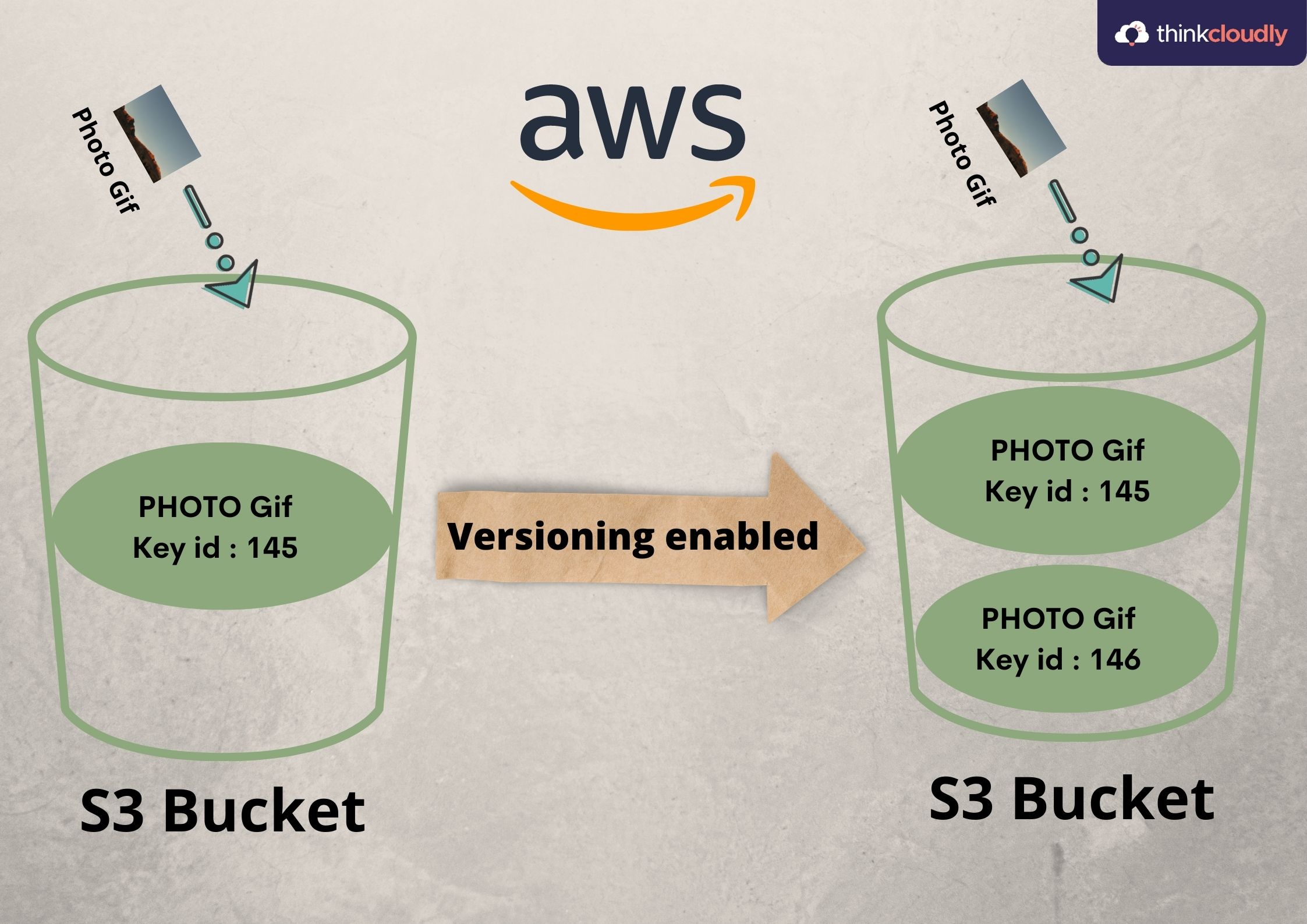
Three states of Buckets:
- Unversioned (default)
- Versioning-enabled.
- Versioning-suspended.
It’s time to enable and test Amazon S3 versioning:
- Log in to the AWS Management Console and type “S3” in the search box.
- You will see an S3 dashboard, click create buckets.
- The next step is to select the Region that is closest to you and enter the name of your bucket.
- Click on the Create Bucket button, leave all the settings the way they are, and scroll down.
- It is important to remember that a bucket’s name should always be unique and should not already exist publicly under a similar name; otherwise, your bucket will not be created.
- We have created our first bucket, click on the name of the bucket to open it.
- Here is a list of many of the features like Objects, Property, Permissions, Metrics, and others.
- Now, let us upload our first object into our bucket in S3.
- Open your browser and save a . Jpg image or file on your local computer.
- Click on Upload.
- Click on Add files.
- Choose an image in the “.jpg” format.

- Leave all the settings as it is and click on Upload.
- Click on the image to open it.
- The image is uploaded to an S3 bucket, so clicking Open will reveal the image in your browser.
- You can now view the bucket’s properties by clicking on it.
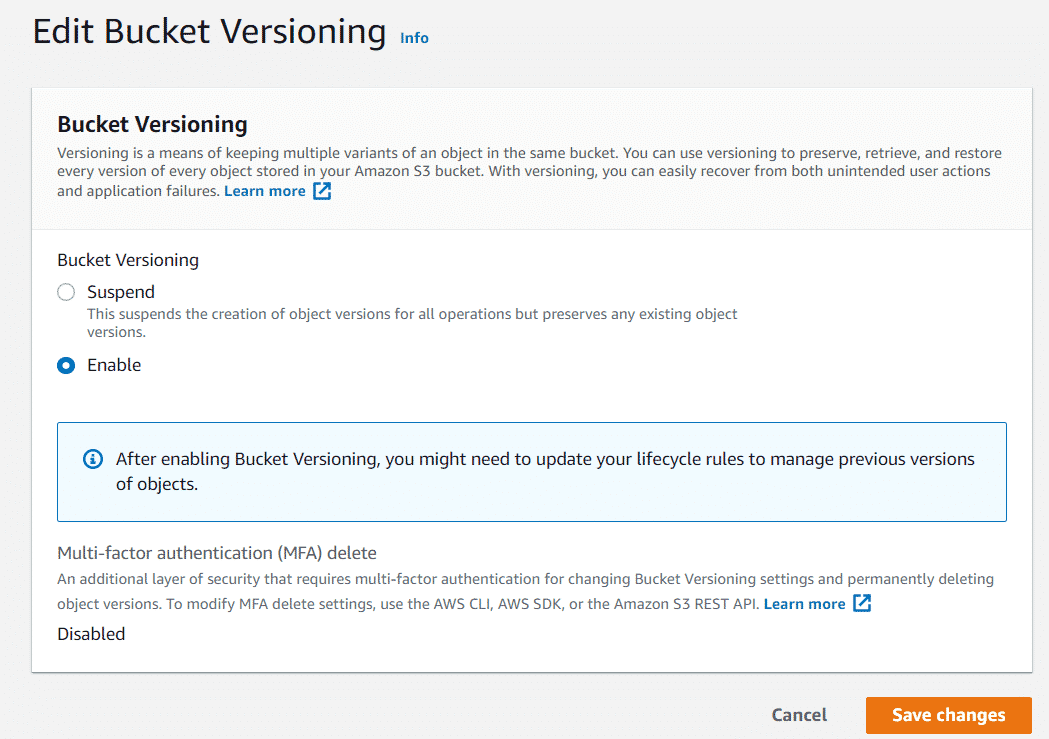
- Click Edit beneath Bucket Versioning in that menu.
- Once Enable is clicked, click Save changes.
- There is now a new option called Show versions that can be enabled.
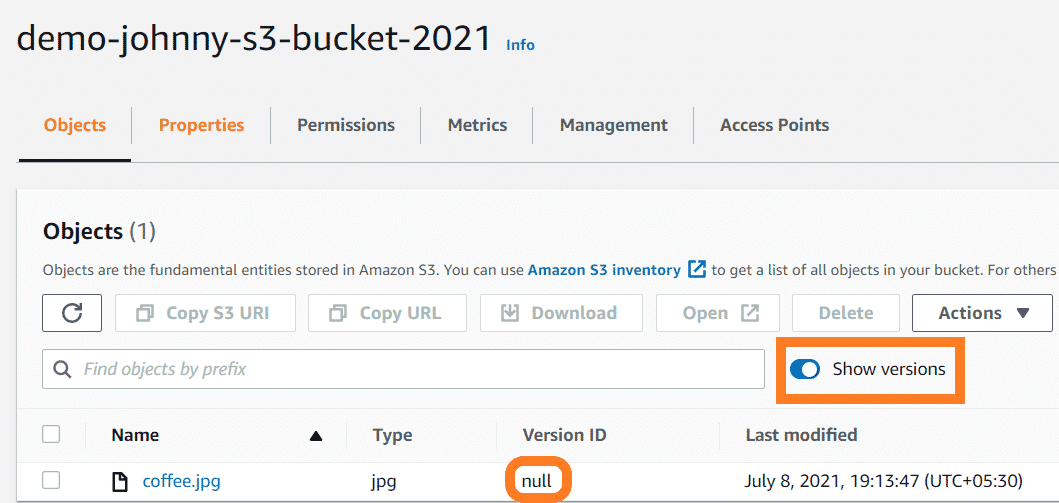
- There will be a new column Version ID which will display the object name but the version id will be null, meaning the file was uploaded to the bucket before versioning was enabled.
- To explore more we are going to upload new files.
- Go back to your bucket page.
- Select any image and click Add files, then click Upload.
- You now need to enable Show versions on the bucket page.
- As we can see, the newly uploaded file contains a Version ID.
- So to get a Version ID you must enable versioning before you upload any file.
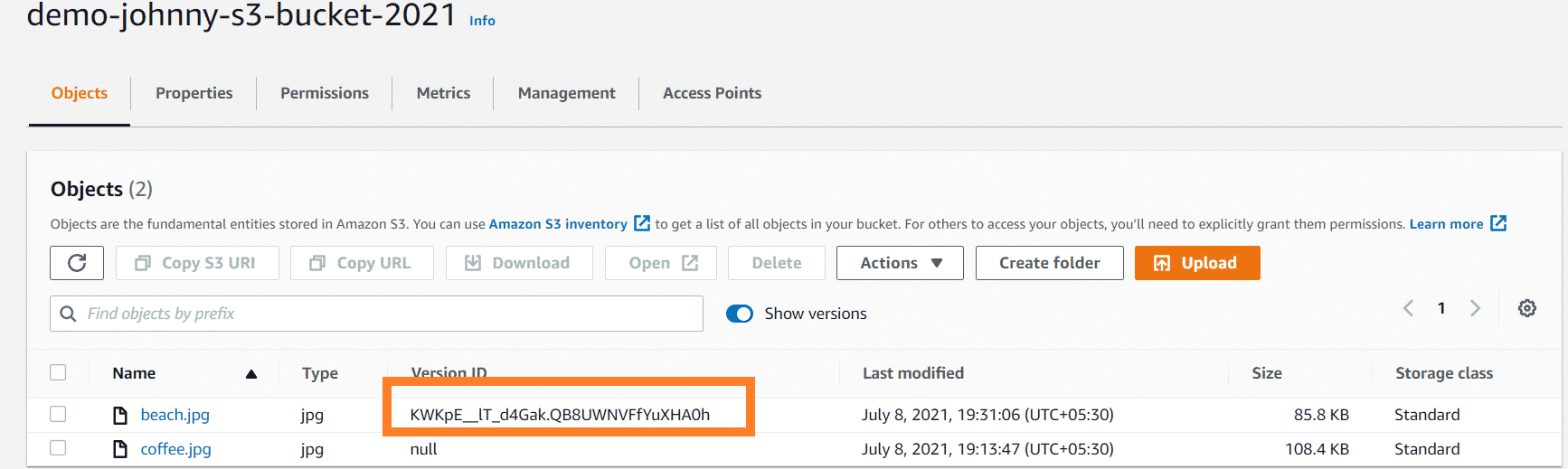
- Therefore, we will reupload the previous file and enable the Show versions option.
- We can see that now it has 2 version IDs.
- Each time we upload a file, the version ID is defined.
- Try to delete the previously uploaded file now by disabling Show Versions.
- Select the file and click Delete Objects.
- It will display a warning as shown below.

- Let’s take a closer look at what is going on, as we are not doing actual deletion. Instead, we are adding delete markers.
- Click on Delete
- That file has been deleted, but if you enable the Show versions option, you will see it still exists with its own version number.
- The file appears to be gone, but actually, it hasn’t been deleted.

- You can delete any delete marker file permanently by selecting that file as the delete marker.
- Click on Delete objects and it will be deleted permanently.
- Go back to the bucket page and enable Show versions.
- You will see that files are deleted. This allows us to restore things.
Versioning protects against deletes that aren’t intended/wanted.
Congratulations!! You have created Amazon S3 versioning and tested it successfully. See you in the next Lab.
Conclusion:
Amazon S3 versioning is a great way to collaborate with team members, protect your data from accidental deletion, and maintain a specific state of an object. Visit our website if you want to learn more about cloud computing technology or have any questions for us!







