
AWS Data Ingestion is a process of getting data from the source system to AWS. This can be done by using one of many cloud-based ETL tools, such as Amazon Athena and Amazon EMR. If you want your ingestion process streamlined, then keep reading!
AWS Data Ingestion: Tools and Architecture
AWS offers a range of data ingestion tools that cater to diverse data integration needs. These tools, such as Amazon Kinesis, AWS DataSync, and AWS Glue, enable efficient and secure data movement from various sources to AWS services. Whether it’s real-time streaming data, large-scale batch transfers, or automated data transformation, AWS data ingestion tools provide the necessary capabilities to ensure seamless data flow into the cloud. To design an effective AWS data ingestion architecture, one can leverage these tools alongside services like Amazon S3, Amazon RDS, and Amazon Redshift, creating robust and scalable solutions that align with specific business requirements.
In the realm of AWS data ingestion, it’s imperative to leverage the right AWS data ingestion tools and techniques to ensure a seamless flow of data into your cloud environment. AWS offers a versatile array of data ingestion tools, such as AWS Glue, AWS Data Pipeline, and AWS Kinesis, each tailored to specific data ingestion requirements. In this seven-step process, we’ll explore the intricacies of these data ingestion tools in AWS, guiding you through the selection, configuration, and execution phases. Whether you’re dealing with batch data or real-time streaming data, mastering these data ingestion techniques within AWS will empower you to efficiently manage and harness the power of your data.
What is AWS Data Ingestion?
AWS Data Ingestion is a service that allows you to move data from your on-premise servers into the cloud.
AWS Data Ingestion is an amazing tool for moving large amounts of information and storing it in AWS so it can be accessed without having to go through all kinds of legal hoops or pay big bucks using other systems.
How AWS helps in data ingestion
AWS architecture offers services and capabilities to quickly and easily ingest multiple types of data, such as real-time streaming data and bulk data assets from on-premises storage platforms, as well as data generated and processed by legacy on-premises platforms, such as mainframes and data warehouses.
Boost your earning potential with AWS expertise. Explore our certified AWS Courses for a high-paying career
There are 3 services offered by AWS
- Amazon Kinesis Firehose
- AWS Snowball
- AWS Storage Gateway
Amazon Kinesis Firehose

- Amazon Kinesis Firehose is a fully managed service for delivering real-time streaming data directly to Amazon S3.
- Kinesis Firehose automatically scales to match the volume and throughput of streaming data and requires no ongoing administration
- Kinesis Firehose can also be configured to transform streaming data before it’s stored in Amazon S3. Its transformation capabilities include compression, encryption, data batching, and Lambda functions.
Note: Kinesis Firehose can concatenate multiple incoming records and then deliver them to Amazon S3 as a single S3 object. This is an important capability because it reduces Amazon S3 transaction costs and transactions per second load.
So now I hope you have a quick glance at AWS cloud computing. If you want to learn more about it, read our blog what is AWS?”
Kinesis Firehose can invoke Lambda functions to transform incoming source data and deliver it to Amazon S3. Common transformation functions include transforming Apache Log and Syslog formats to standardized JSON and/or CSV formats.
AWS Snowball
Snowball is a petabyte-scale data transport solution that uses secure appliances to transfer large amounts of data into and out of the AWS cloud. Using Snowball addresses common challenges with large-scale data transfers including high network costs, long transfer times, and security concerns. Migrate bulk data from on-premises storage platforms and Hadoop clusters to S3 buckets.
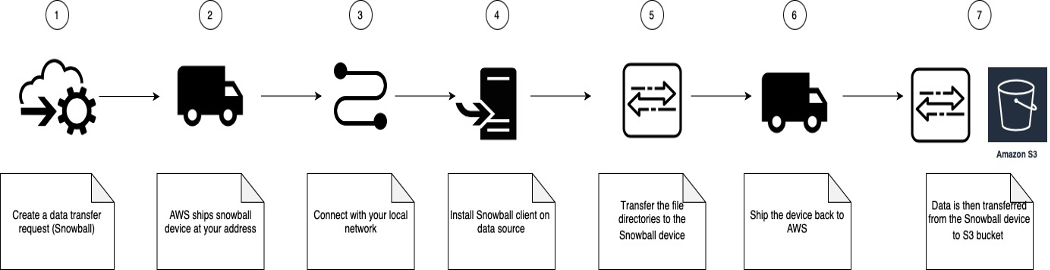
Follow the below 7 Easy Steps for AWS Data Ingestion methods:
- Create a job in the AWS management console for data transfer using Snowball.
- Snowball appliances will be automatically shipped to your address.
- After a Snowball arrives, connect it to your local network
- Install the Snowball client on your on-premises data source.
- Use the Snowball client to select and transfer the file directories to the Snowball device.
- Ship the device back to AWS.
- Once AWS receives the device, data is then transferred from the Snowball device to the S3 bucket and stored as S3 objects in their original/native format.
Notes: The Snowball client uses AES-256-bit encryption. Encryption keys are never shipped with the Snowball device, so the data transfer process is highly secure.
AWS Storage gateway
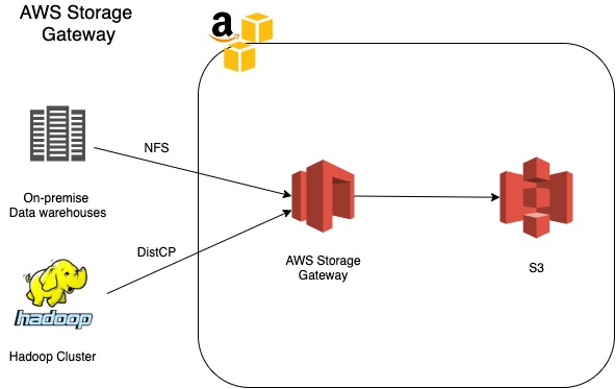
Integrate legacy on-premises data processing platforms with AWS S3 (Data lakes) using AWS Storage gateway. It uses an NFS connection to write the files on mount points.
- Files written to this mount point are converted to objects stored in Amazon S3 in their original format.
- Integrate applications and platforms that don’t have native Amazon S3 capabilities — such as on-premises lab equipment, mainframe computers, databases, and data warehouses with Amazon S3.
Note: This also allows data transfer from an on-premises Hadoop cluster to an S3 bucket.
As you have learned the AWS Data Ingestion Services. You can also clarify your concepts on AWS Fundamental Services.
Conclusion
Everyone would have a question at last after reading this.
Which one should you prefer for my business requirements?
A Simple Answer is “It depends.”
- When you have real-time streaming data and you would like to transform, encrypt, or compress on the fly, then your preferred choice should be Amazon kinesis firehose.
- In case of a large amount of data in petabytes, then instead of transferring massive data on the network, it consumes network bandwidth and can cost you a lot. Then you should go for AWS Snowball.
- When you would like to transfer data to AWS S3 or FSx using SMB protocol or NFS. You can create a storage gateway and join it with an active directory domain. Finally, mount the storage gateway endpoint in the existing on-premise virtual machine.
Cloud seems interesting to you. Refer to more blogs:
- Amazon Kinesis and its capabilities
- AWS WAF – Everything you need about web application firewall
- AWS Lambda – A beginner’s guide to the cloud
- AWS System Manager – 7 tips to get the best out of it
- Introduction to AWS EC2
Walk through our courses for more detailed knowledge over these topics.








