DynamoDB is an Amazon Web Services (AWS) NoSQL database service that offers scalability and high availability with low latency at the cost of consistency. By using DynamoDB, developers can build serverless applications that are scalable, reliable, and efficient.
It supports two types of storage engines — standard and global secondary indexes. Developers can choose between these storage engines based on their requirements and change their decision as and when required without any downtime or data loss, as DynamoDB provides seamless data migration support.
Exploring Amazon DynamoDB: Scalable NoSQL Database Service
Amazon DynamoDB is a fully managed NoSQL database service provided by AWS. It offers high-performance and seamless scalability to meet the requirements of modern applications. DynamoDB is designed to handle massive amounts of data and traffic, making it well-suited for use cases that demand low-latency access and real-time responsiveness. With features like automatic scaling, built-in security, and support for document and key-value data models, DynamoDB simplifies database management tasks and allows developers to focus on building applications without worrying about the underlying infrastructure. It’s an integral part of the AWS ecosystem, offering a reliable and flexible solution for storing and retrieving structured and semi-structured data at any scale.
Let’s take an overlook at the most important concepts of DynamoDB.
What is DynamoDB?
Amazon DynamoDB is a database service that is flexible NoSQL and performs quite fast. Amazon DynamoDB is completely managed over the cloud and gives supporting assistance to both documents and key-value store models. It holds many functionalities, from a flexible data model and reliable performance to automatic scaling of throughput capacity. These functionalities make it the best fit for mobile, web, gaming, and many more applications and platforms. Amazon DynamoDB offers fast and predictable performance. Giving such outstanding performance, it provides single-digit millisecond latency at any scale.
Amazon DynamoDB is a versatile and highly scalable NoSQL database solution offered by AWS, making it an ideal choice among AWS serverless database options. Whether you’re exploring DynamoDB for its serverless capabilities or preparing for a DynamoDB certification, it’s crucial to familiarize yourself with the database’s intricacies to ace interview questions on DynamoDB. DynamoDB’s serverless architecture ensures automatic scaling, eliminating the need for manual provisioning, and its adaptability to various use cases makes it a standout choice in the world of cloud-based databases.
Features of Amazon Dynamo DB
- Fully managed cloud database service – It makes it easy to deploy, operate, and scale serverless applications as it works as a fully managed database service over the cloud.
- Low cost – With Amazon DynamoDB, there are no servers to manage—you pay only for storage and throughput capacity (in units of reads and writes).
- High availability – Amazon replicates the data across multiple Availability Zones in an AWS Region, leading to the increased availability of the data.
- Efficient– Using a client-side library or working directly with one of our APIs, you can get started quickly and efficiently by creating tables for your AWS Lambda functions, compute engine instances, IoT devices, or other uses.
- Fast – The data is stored on Solid State Disks (SSDs), which provide more immediate access to read/write data from disk than traditional spinning disk drives.
Boost your earning potential with AWS expertise. Explore our certified AWS Courses for a high-paying career
Why use a serverless database?
If you’re building a website or web application, you need a database to store your data. Many developers use cloud-based databases to take advantage of scalable resources that can be scaled on demand. This scalable infrastructure also allows for incredible ease in scalability and elasticity—two major benefits when developing a new product. A serverless database is ideal if you’re comfortable working with third-party services and aren’t looking for ultimate control over your data. In other words, it’s not for everyone. However, Amazon Web Services (AWS) offers a variety of highly scalable database options perfect for modern applications. In today’s post, we will go over what AWS offers in terms of cloud-based database solutions.

Core concepts of an AWS DynamoDB
Table: The collection of items is called a table, or you can say it is the collection of data records.
Items: A collection of attributes is called an Item. The primary key of the Table can identify each item.
Attributes: Attributes are the data that is attached to the items.
Partition Key: It is a unique primary key.
Partition key and sort key: It combines the primary key with one or more attributes like Student name and Student ID.
Comparison Between Amazon DynamoDB and Other Databases
The most popular databases available today are Apache Cassandra, Redis, MongoDB, and MySQL. Let us look at how Amazon DynamoDB compares with these traditional databases. Among them, AmazonDynamoDB is a key-value store developed keeping cloud scalability in mind. So, it doesn’t come across as a surprise when people say that it isn’t built for all possible use cases as other open-source or proprietary databases are.
But then again, there is an irony here since AWS itself is built on open-source technology stacks like Linux. Many of its services are proprietary or paid offerings that aren’t better than their counterparts!
Creating Table in DynamoDB
- log in to your AWS Management Console account and search and open DynamoDB from the search bar.
- Click on Tables and then Create Table.

- Give your Table a name and a unique Partition key. You can also go for the data type of the Partition Key.

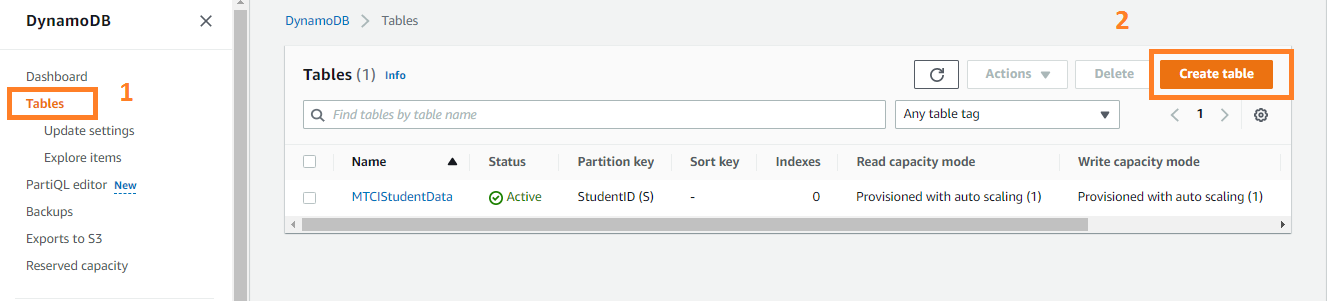

Click on Create Table.
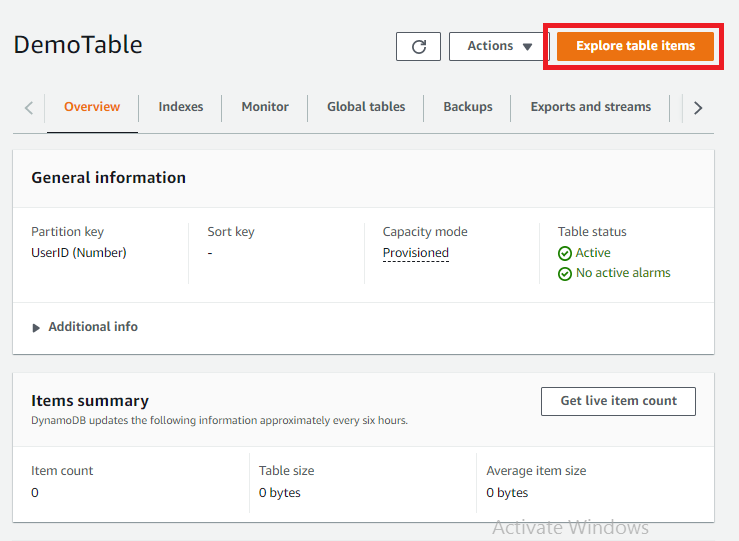
- Open the Table by clicking on it. Now, click on Explore Table to add/create new items in the Table.

- You can add your first item to the Table by clicking on the Create item in the menu, as shown below.

- The next step goes for entering the value for the Partition Key. You may add new attributes to the Table by selecting its data type from the dropdown list. ( Here, Name and Age are the unique attributes added to the Table.)


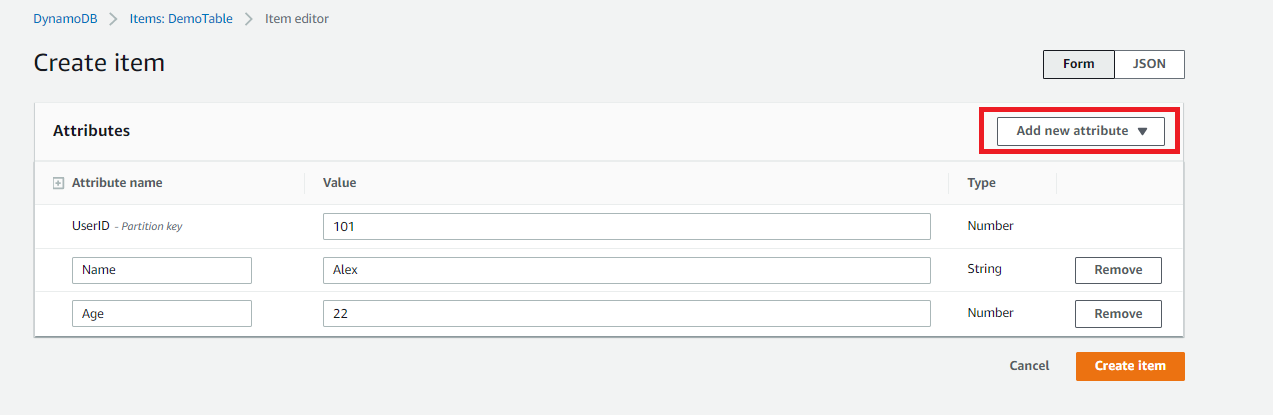
Click on Create Item.
Hurray! You have successfully created your first DynamoDB Table in AWS. Now, you can try applying filters to the Table to search for a particular record.
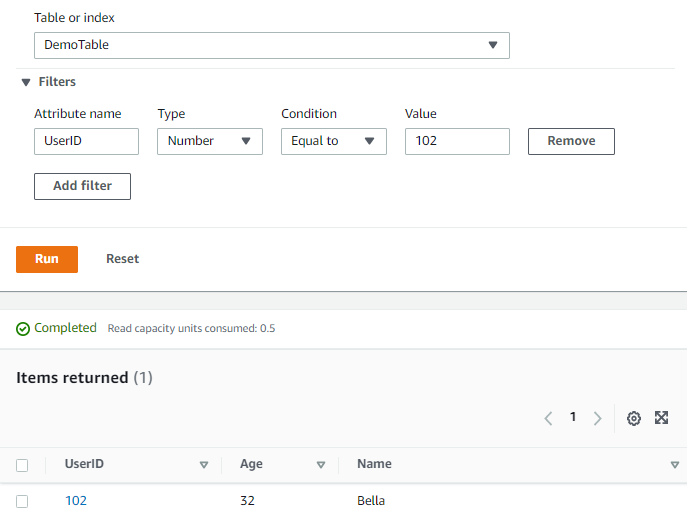
AWS knowledge is helpfull for high paying career. Explore our more resources to get trained for AWS career.
- Explore AWS Route 53 interview questions.
- Practice for your interview with AWS live project training.
- Read top AWS IAM interview questions.
- Read concepts of data ingestion in AWS.
- Read top EC2 interview questions and answers.
Conclusion:
We have taken a detailed look at AWS’s serverless database: DynamoDB. We saw how its ability to scale on-demand while maintaining fast performance and high availability makes it a great fit. If you are looking for an easy way to get started with serverless databases, then DynamoDB is worth considering. It is also worth noting that many other options are available, such as Azure Cosmos DB and Google Cloud Spanner. We will be writing about them in future posts, so stay tuned!
You can refer to our courses for more detailed knowledge of various topics.









