Imagine being in the middle of your regular work routine, diligently configuring and managing AWS services, when suddenly, everything goes haywire. Your AWS console connections start experiencing problems, and you’re bombarded with confusing 404 Page Not Found and 504 Gateway Timeout errors. Frustration builds up as you try to make sense of the situation. Seeking answers, you turn to various news sources and discover the disheartening truth: AWS is facing a widespread outage. You reluctantly confirm this by checking the AWS health checker, and with a heavy heart, you’re forced to temporarily pause your work.
That’s what happened to me today. Let’s dive into the details of this unexpected AWS outage and unravel the reasons behind its occurrence.
Highlights of AWS outage:
Problem: Increased Error Rates and Latencies
Start time: June 13, Between 11:49 AM PDT and 3:37 PM PDT
Resolve time: June 13, 3:42 PM PDT
Root cause: A subsystem responsible for capacity management in AWS Lambda encountered issues, resulting in errors for users.
What is an Outage?
An outage refers to a period of time when a system, service, or network is unavailable or not functioning as intended. It often involves disruption or failure in the infrastructure or technology supporting the system, resulting in the inability of users to access or use the service. Outages can occur due to various reasons, such as technical glitches, software bugs, hardware failures, cyber-attacks, or maintenance activities. During an outage, users may experience service disruptions, errors, slow performance, or complete unavailability of the affected system or service.
What problem did the users face during the AWS outage?
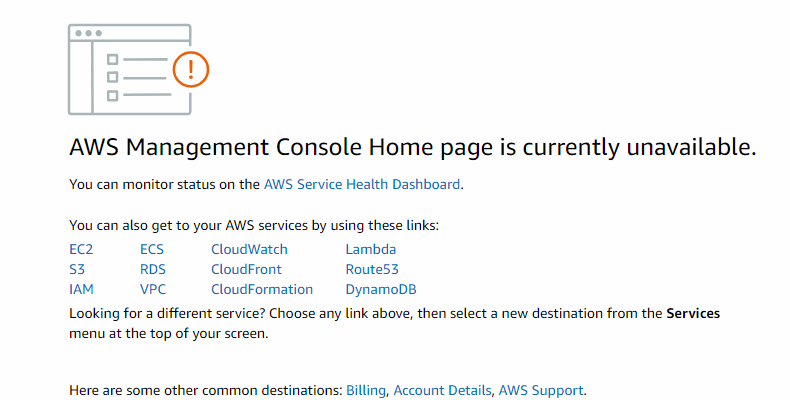
According to the AWS Health Dashboard, users encountered difficulties connecting to the AWS console, resulting in service disruptions. Error messages such as 404 Page Not Found and 504 Gateway Timeout were prevalent. Additionally, authentication errors arose while accessing the AWS Management Console and utilizing services like Cognito and IAM STS. Customers also faced challenges when attempting to initiate support calls or chats with AWS Support.
Boost your earning potential with AWS expertise. Explore our certified AWS Courses for a high-paying career
The Butterfly Effect: How the AWS Outage Triggered a Chain Reaction
AWS services have a profound impact on companies that utilize them, providing them with the necessary infrastructure, scalability, and flexibility to power their operations. By leveraging AWS’s computing power and storage resources, businesses can deploy and run their applications efficiently, regardless of scale or complexity. The ability to scale resources up or down based on demand ensures optimal performance and cost efficiency. Additionally, AWS’s global availability and low-latency connectivity enables companies to reach their customers seamlessly, regardless of their geographical location. With robust security measures, managed database services, AI capabilities, and a suite of developer tools, AWS empowers companies to innovate, scale, and drive their business forward.
The AWS outage sent shockwaves across the digital landscape, creating a chain reaction that impacted not only AWS itself but also its high-profile clients. From major companies like McDonald’s app, Instagram, FIFA, and TikTok, to a multitude of other businesses and platforms, the outage cast a shadow of uncertainty and brought operations to a grinding halt.
Many AWS services also were affected such as the most important department of AWS which is AWS support call and chat system, AWS Console, AWS Account Management, AWS CloudFormation, Amazon Elastic File System, EC2 Image Builder, and Alexa.


Is the problem solved?
Yes, The AWS Health Dashboard reported “Jun 13, 2:02 PM PDT Between 11:49 AM and 1:40 PM PDT, we experienced degraded contact handling in the US-EAST-1 Region. Callers may have failed to connect and chats and tasks may have failed to initiate. Agents may also have experienced issues logging in or being connected with end customers. The issue has been resolved and the service is operating normally.”
Root cause
According to the company’s official statement on its website, the underlying cause of the problem stemmed from AWS Lambda, a service that enables customers to execute code for a variety of applications.
Learning from the AWS Outage: Steps Towards a More Robust Future
The incident served as a wake-up call for the entire industry, forcing businesses to reevaluate their reliance on AWS and devise new strategies to protect themselves from future risks. It highlighted the need for resilience and redundancy in our increasingly digitized world, pushing companies to explore alternative solutions and fortify their infrastructure against potential outages. The aftermath of the outage prompted a collective rethinking of the way we build and maintain our digital systems, emphasizing the importance of preparedness and the ability to swiftly adapt in the face of unforeseen challenges.
The recent AWS outage has highlighted the importance of building a robust and resilient infrastructure to minimize the impact of such incidents. Here are some steps that can be taken toward a more robust future:
- Embrace distributed architecture to minimize localized outages.
- Implement a multi-cloud strategy for redundancy and resiliency.
- Conduct chaos engineering exercises to identify vulnerabilities.
- Follow CI/CD practices for continuous testing and deployment.
- Learn from incidents through thorough post-incident reviews.
- Leverage automated scaling to handle fluctuating workloads.
- Establish failover mechanisms and disaster recovery plans.
- Regularly back up critical data and test recovery processes.
- Design systems with isolation and compartmentalization for resilience.
- Utilize robust monitoring and alerting systems for a proactive response.
History
The recent AWS disruption, although smaller in duration and impact compared to the 2017 Amazon S3 outage, was significant for the company’s cloud business, which heavily relies on data-hosting services. In a separate incident in December Year, disruptions to Amazon’s cloud services affected popular streaming platforms, including Netflix and Disney+, as well as Robinhood and Amazon’s own e-commerce website during the holiday season.
Conclusion
In conclusion, the AWS outage highlighted the importance of AWS infrastructure for businesses, including popular services like Amazon Alexa. The incident emphasized the need for robust infrastructure, scalability, and redundancy to minimize disruptions. Steps towards a more robust future include embracing distributed architecture, implementing multi-cloud strategies, establishing failover mechanisms, and conducting post-incident reviews. By proactively addressing challenges, businesses can ensure uninterrupted operations and a seamless user experience.